Timeouts on Heroku? It’s Probably You
2
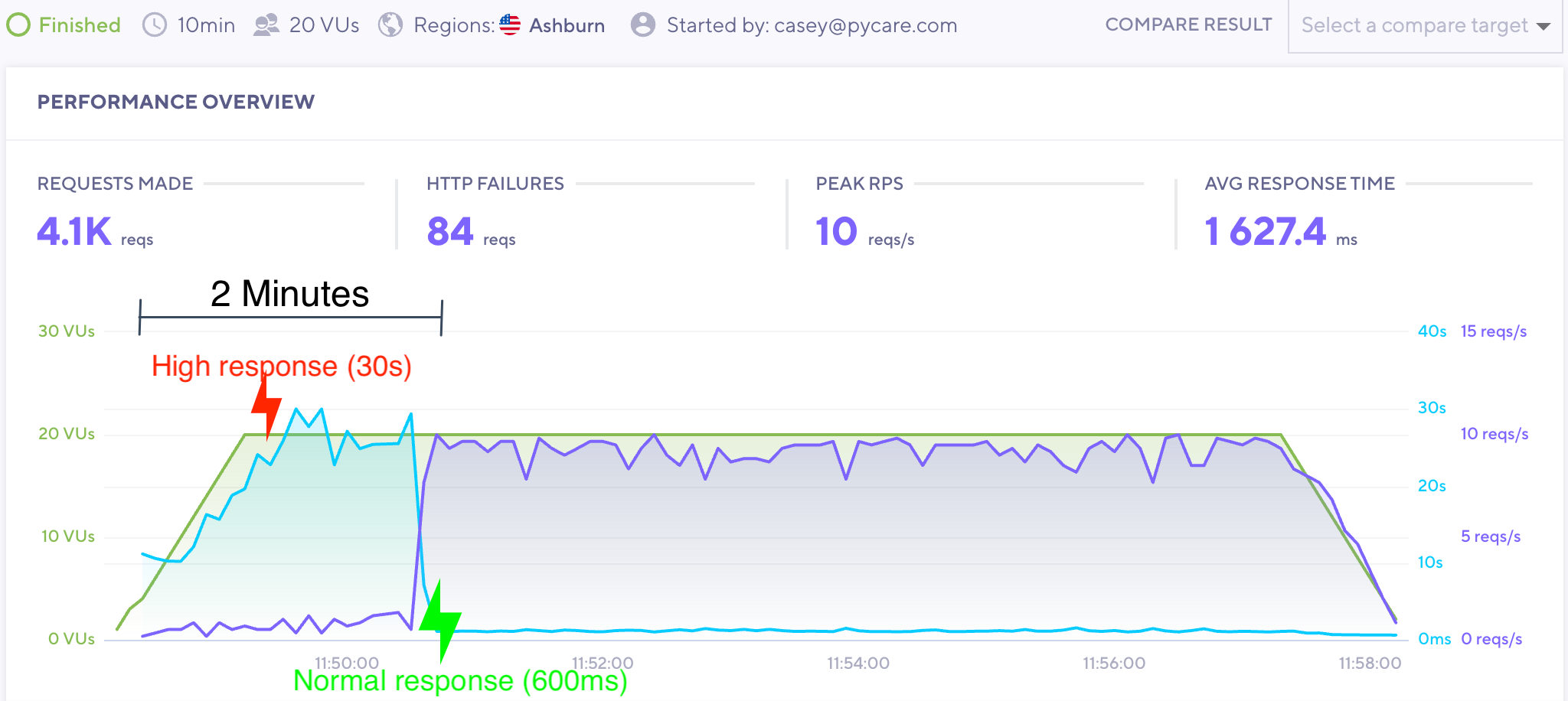
Have you ever logged into Heroku to see a short stretch of request failures, high response times, and H12 Request Timeout errors?

The first thing that comes to mind is ‘something is wrong with Heroku!‘. But you check their status page and there are no reported problems.

Trust me I have been there! Here is proof:
Unable to solve the problem, you think ‘it must be gremlins’ and move on. In this post I want to show you why it’s probably not gremlins and it’s probably not Heroku.
The issue is likely that you do not have proper timeouts set within your own code. Let’s discuss the problem, do an experiment to demonstrate the issue, then offer some solutions.
Note: I will cover the standard synchronous mode in this post, and will write about asyncrhonous (gevent) situations in another article.
The Problem
Your web application depends on different services, be it a PostgreSQL database, redis cache, or an external API. At some point one or more of those services may slow down, either due to a temporary issue, or something of your own design such a slow database query.
You may also experience slowdowns due to unexpected load on your web site. This can come from bots that quickly overwhelm your app.
Without proper timeouts, these short slowdowns cascade into longer ones lasting beyond 30 seconds. If Heroku does not receive a response from your app within 30 seconds, it returns an error to the user and logs a H12 timeout error. This does not stop your web app from working on the request.
Demonstration
To demonstrate the problem, I am going to create a Flask app that simulates a very slow API service. The app is served with gunicorn and logs each visit in redis via a counter. The first 75 requests are slowed way down, taking 45 seconds to respond. The rest of the requests are processed in 600 milliseconds. Here is the script:
# Procfile
web: gunicorn app:app
# app.py
import os
import time
from flask import Flask
import redis
app = Flask(__name__)
r = redis.from_url(os.environ.get('REDIS_URL', 'redis://localhost:6379'))
@app.route('/')
def hello_world():
r.incr('counter', 1)
if int(r.get('counter')) < 75:
time.sleep(45)
else:
time.sleep(0.6)
return 'Hello World!'
Let’s run this app with the wonderful K6 load testing tool for 10 minutes.
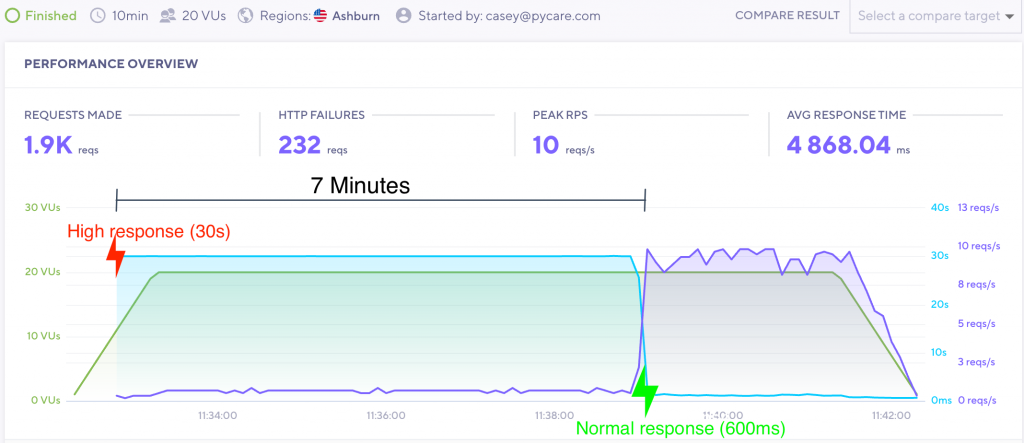
Focus on the blue line, which is the overall response time. The response time immediately goes to 30 seconds and stays there for 7 minutes! This is despite the slow request portion lasting only 2 minutes. As you can see, there is a residual effect from the slow response, in that the app is trying to process requests long after the incident is over.
To make matters worse, any slowdowns that occur near the end of that 7 minutes will easily extend the time in failure. So an unstable service could make your app unusable for over an hour if the problem continues to reappear.
The Solution
Let’s run the scenario again but set a 10 second timeout in gunicorn, like this:
# Procfile web: gunicorn app:app --timeout 10
This timeout kills and restarts workers that are silent for however many seconds are set. Here is the same scenario with a 10 second timeout:
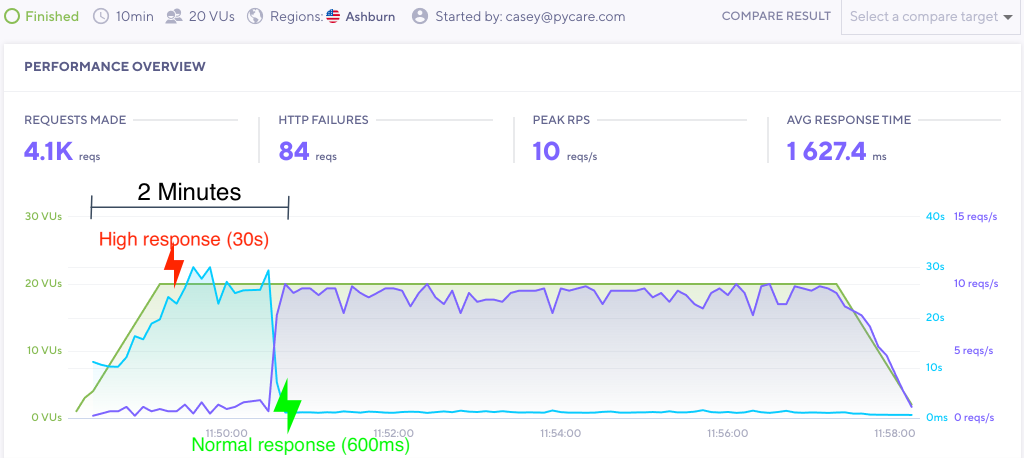
See how fast that recovery is? With a 10 second timeout the response time gradually increases, but goes back to normal almost immediately once the problem goes away.
An Alternate Solution – Set a Timeout on the API Request
Now I know someone out there is saying ‘duh Casey, just set a timeout when you call the API!’. Well you are not wrong. If you use requests to handle your API call, you can simply set a timeout on the API request like so:
import requests r = requests.get(url, timeout=3)
In this scenario our gunicorn timeout may not be needed, as requests will throw an error for any request that takes longer than 3 seconds. Let’s try our scenario again with this timeout in place:
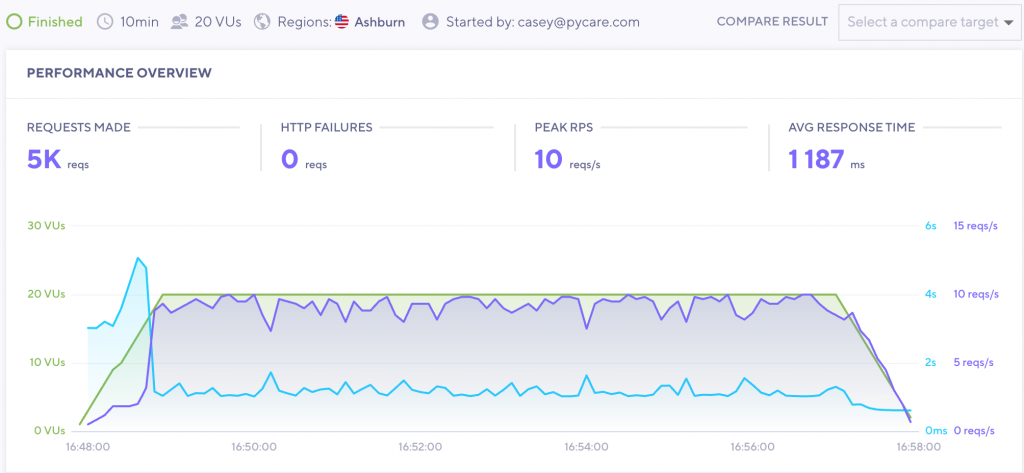
The response time slowly climbs up to 5 seconds, but quickly resolves once the problem goes away.
This approach provides another benefit, in that we can check our error logs and see what caused the problem. Rather than a generic Heroku timeout error, we can see that a specific API service timed out during a particular timeframe. We can even handle the error gracefully and display a message to our users while the API is unavailable:
import requests
try:
requests.get(url, timeout=3)
except requests.exceptions.Timeout:
context['message'] = 'This service is not available.'
We can set timeouts on other services as well, such as Elasticsearch:
ELASTICSEARCH={
'default': {
'hosts': os.environ.get('ELASTIC_ENDPOINT', 'localhost:9200'),
'http_auth': os.environ.get('ELASTIC_AUTH', ''),
'timeout': 5,
},
}
The goal is that the lower-level service catches the timeout situation first, but the gunicorn timeout is there to catch the broader unexpected situations.
You Need Both
Although you can catch an API timeout with requests, heavy traffic and other situations can still drive your app to need the gunicorn timeout. So it is important to implement both of these strategies.
Low Timeout Limitations
Timeouts are great and all, but sometimes setting a low timeout cuts off a critical capability of your app.
For example, if it takes 15 seconds to generate a page that is then served via cache, setting a timeout of 10 seconds will eliminate your ability to load that page. Or maybe you need to upload files and that takes 20 seconds. So you cannot set a gunicorn timeout lower than 20 seconds.
The bottom line is that your gunicorn timeout is limited to the single function that takes the longest to run.
The solution is to refactor those parts of your app. You can do this by:
- Use of background jobs to process long-running tasks
- Upload files directly to S3
- Improve slow database queries by adding an index
- Caching via background jobs
Summary – Timeouts Make Your App Stable and Resilient
So where should you add timeouts? Everywhere! We need service-level timeouts so we know when our service is having issues. We need gunicorn timeouts for unforeseen circumstances and so that our app recovers quickly after being overloaded.
Remember, lowering timeouts is an iterative process. Optimize your app, then lower your timeouts. With proper timeouts in place your app will handle slowdowns and outages well, recovering very quickly while allowing developers to identify the issues involved.